
How to use Order Statistic Filters with OpenCV
[caption id="attachment_789" align="alignnone" width="471"]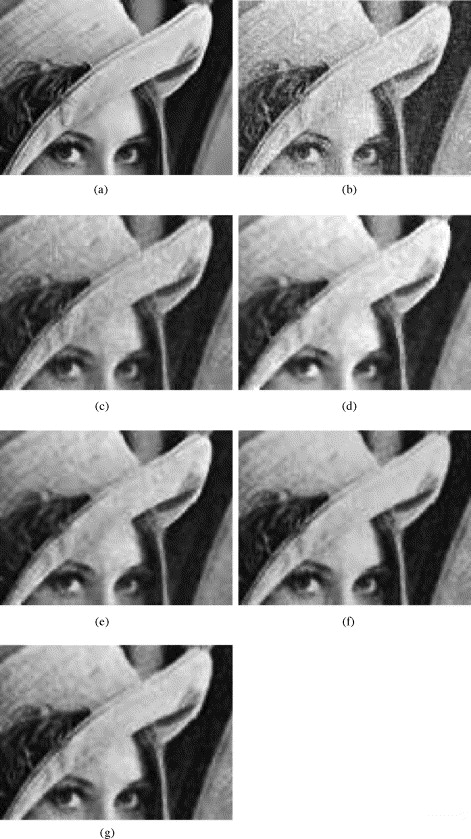 Order Statistic Filters[/caption]
Order Statistic Filters[/caption]
Order Statistic filters are filters whose response is based on ordering/ranking the pixels
containing in the 3x3 window.
1. Median filter
The value of the centre pixel is replaced by the median value of its neighbourhood pixels. The median is taken after arranging the pixel values in ascending order and then taking the middle value. Use the following function,
CV_MEDIAN (median blur) - finding median of param1×param1 neighborhood (the neighborhood is square).
2. Max filter
The max filter uses the maximum value of its neighbourhood pixels to replace the centre pixel value.
The function dilates the source image using the specified structuring element that determines the shape of a pixel neighborhood over which the maximum is taken. Image Understanding and Processing (OpenCV)
3. Minimum filter
The minimum filter uses the minimum value of its neighbourhood pixels to replace the centre pixel value.
The function erodes the source image using the specified structuring element that determines the shape of a pixel neighborhood over which the minimum is taken.
Sample Code
[sourcecode language="cpp"]
#include "stdafx.h"
#include <cv.h>
#include <cxcore.h>
#include <highgui.h>
int _tmain(int argc, _TCHAR* argv[])
{
IplImage *img = cvLoadImage("apple noise.jpg");
IplImage *dst1=cvCreateImage(cvSize(img->width,img->height),8,3);
//cvSmooth(img,dst,CV_MEDIAN,3,3); Median Filter
//cvDilate(img,dst,NULL,1); Max Filter
//cvErode(img,dst,NULL,1); //Max FiltercvNamedWindow
cvNamedWindow("Image:");
cvShowImage("Image:", img);
cvNamedWindow("DST:");
cvShowImage("DST:", dst1);
cvWaitKey(0);
cvDestroyWindow("Image:");
cvReleaseImage(&img);
cvDestroyWindow("DST:");
cvReleaseImage(&dst1);
return 0;
}
[/sourcecode]
Order Statistic Filters[/caption]Order Statistic filters are filters whose response is based on ordering/ranking the pixels
containing in the 3x3 window.
1. Median filter
The value of the centre pixel is replaced by the median value of its neighbourhood pixels. The median is taken after arranging the pixel values in ascending order and then taking the middle value. Use the following function,
void cvSmooth( const CvArr* src,
CvArr* dst,
int smoothtype=CV_MEDIAN,
int param1=3, int param2=3);
CV_MEDIAN (median blur) - finding median of param1×param1 neighborhood (the neighborhood is square).
2. Max filter
The max filter uses the maximum value of its neighbourhood pixels to replace the centre pixel value.
void cvDilate(const CvArr* src,
CvArr* dst,
IplConvKernel* element=NULL,
int iterations=1)
The function dilates the source image using the specified structuring element that determines the shape of a pixel neighborhood over which the maximum is taken. Image Understanding and Processing (OpenCV)
3. Minimum filter
The minimum filter uses the minimum value of its neighbourhood pixels to replace the centre pixel value.
void cvErode(const CvArr* src,
CvArr* dst,
IplConvKernel* element=NULL,
int iterations=1)
The function erodes the source image using the specified structuring element that determines the shape of a pixel neighborhood over which the minimum is taken.
Sample Code
[sourcecode language="cpp"]
#include "stdafx.h"
#include <cv.h>
#include <cxcore.h>
#include <highgui.h>
int _tmain(int argc, _TCHAR* argv[])
{
IplImage *img = cvLoadImage("apple noise.jpg");
IplImage *dst1=cvCreateImage(cvSize(img->width,img->height),8,3);
//cvSmooth(img,dst,CV_MEDIAN,3,3); Median Filter
//cvDilate(img,dst,NULL,1); Max Filter
//cvErode(img,dst,NULL,1); //Max FiltercvNamedWindow
cvNamedWindow("Image:");
cvShowImage("Image:", img);
cvNamedWindow("DST:");
cvShowImage("DST:", dst1);
cvWaitKey(0);
cvDestroyWindow("Image:");
cvReleaseImage(&img);
cvDestroyWindow("DST:");
cvReleaseImage(&dst1);
return 0;
}
[/sourcecode]










0 comments: